用CPLD實(shí)現(xiàn)嵌入式平臺(tái)上的實(shí)時(shí)圖像增強(qiáng)

對(duì)于連續(xù)圖像P,其局部邊緣可由對(duì)應(yīng)空間梯度的幅值
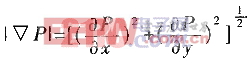
,取其一階近似ΔPi,j=2Pi,j-Pi,j-Pi-1,j,可得圖像{Pi,j|i=1,2,...,n;j=1,2,...,m}在(i,j)的邊緣信息
如果不計(jì)Pi,j的取值范圍,可直接對(duì)圖像{Pi,j|i=1,2,...,n;j=1,2,...,m}進(jìn)行修正:
P′i,j=Pi,j+ΔPi,j,
其中,P′i,j表示Pi,j修正后的值顯然,圖像{Pi,j|i=1,2,...,n;j=1,2,...,m}按此規(guī)則修正后邊緣值的變化更為強(qiáng)烈,邊緣更為突出,可達(dá)到邊緣增強(qiáng)的效果同時(shí),由于在原圖像上疊加了梯度值,使得修正后的圖像的頻譜有一定的擴(kuò)展但由于沒(méi)有對(duì)Pi,j的取值作約束, 這樣處理后的象素值可能會(huì)溢出,例如對(duì)于每個(gè)色彩通道為8位的圖像,處理后的數(shù)值可能會(huì)大于255或小于0因此,通常要對(duì)其進(jìn)行歸一化處理,即:
Pnew=255%26;#215;(P′-P′min)/(P′max-P′min)
但用硬件實(shí)現(xiàn)乘除運(yùn)算可能會(huì)占用很多資源,上述公式即便以運(yùn)算實(shí)現(xiàn)都是很不經(jīng)濟(jì)的本文采用預(yù)拉伸加飽和/截止的方法,在不犧牲頻率特性的基礎(chǔ)上達(dá)到減少計(jì)算量的目的
考察ΔPi,j與Pi,j的直方圖,分別取得它們的右峰值所對(duì)應(yīng)的橫座標(biāo),記為GΔ和G,并找到k,使得kGΔ+G=255,則修正公式變?yōu)镻′ i,j=Pi,j+kΔPi,j其中kΔPi,j可以LUT實(shí)現(xiàn)修正后的P′i,j可在[0,255]上進(jìn)行飽和/截止運(yùn)算
2 用CPLD實(shí)現(xiàn)實(shí)時(shí)的圖像增強(qiáng)
本文所采用的改進(jìn)圖像增強(qiáng)算法的主要成份是差分累加以及飽和/截止這些運(yùn)算都是加減法及邏輯運(yùn)算,都屬于ALU的簡(jiǎn)單操作,適合硬件實(shí)現(xiàn)本文采用 CPLD實(shí)現(xiàn)所提出的算法以對(duì)具有30fps的1280 1024 RGB圖像計(jì)算ΔPi,j為例,每計(jì)算一點(diǎn)ΔPi,j需要4次加(減)運(yùn)算,即總的需要1280 1024 5;3 30 4=471,895,200次加(減)運(yùn)算如果采用的DSP的速度是100MHz,且假定所有運(yùn)算都是單周期的,則僅僅該運(yùn)算就需要4.7s!所以采用 CPLD實(shí)現(xiàn)某些運(yùn)算是必需的
圖3 圖像增強(qiáng)算法的硬件實(shí)現(xiàn)結(jié)構(gòu)
采用CPLD實(shí)現(xiàn)運(yùn)算(例如邊緣處理中涉及的求梯度運(yùn)算),還需解決數(shù)據(jù)的暫存問(wèn)題本文以一片高速SRAM作為數(shù)據(jù)緩沖區(qū)由于圖像數(shù)據(jù)的采樣輸入的頻率也很高,需要充分合理地安排好每一次操作的時(shí)序,充分利用已參與運(yùn)算的數(shù)據(jù)及中間結(jié)果,減少數(shù)據(jù)進(jìn)出SRAM的次數(shù)
2.1 基于E1-DSP的網(wǎng)絡(luò)圖像采集平臺(tái)
在分析具體實(shí)現(xiàn)方法前,先簡(jiǎn)要介紹所采用的硬件平臺(tái)該平臺(tái)主要用于遠(yuǎn)程圖像采集和以太網(wǎng)傳輸,其圖像通道結(jié)構(gòu)如圖1所示
OV9620是CMOS的數(shù)字圖像傳感器,負(fù)責(zé)采集連續(xù)的數(shù)字圖像;中央處理器使用德國(guó)HYPERSTONE公司的E1系列RISC DSP,它集DSP和RISC于一身,可以加載OS,方便地實(shí)現(xiàn)任務(wù)調(diào)度內(nèi)存管理等功能,大大提高系統(tǒng)的總體性能;CPLD的基本功能是作為E1總線接口控制模塊,本文還將用它實(shí)現(xiàn)圖像增強(qiáng)運(yùn)算
2.2 算法的總流程
為了實(shí)現(xiàn)實(shí)時(shí)的讀寫(xiě)和運(yùn)算,需要由外部電路產(chǎn)生24MHz%26;#215;4的時(shí)鐘EXCLK作為讀寫(xiě)時(shí)鐘,所有時(shí)序都由CMOS時(shí)鐘和EXCLK控制,可以做到完全同步具體流程如圖2所示
(1)在CMOS時(shí)鐘到來(lái)時(shí),從CMOS傳感器的數(shù)據(jù)輸出口采集Pi,j,并實(shí)現(xiàn)加法運(yùn)算RESULT=Pi,j+Pi,j,同時(shí)用EXCLK的第0個(gè)時(shí)鐘向SRAM寫(xiě)入P′i,j-1或P′i,m-1 (本行最后一個(gè)數(shù)據(jù),下一次操作應(yīng)換行);
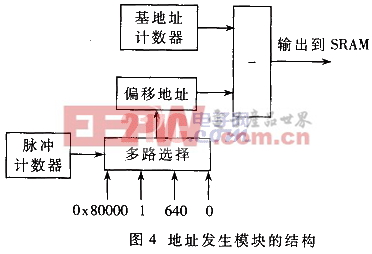
(2)在EXCLK的第1個(gè)時(shí)鐘鎖存RUSELT,由SRAM讀入Pi-1,j,并做減法運(yùn)算RESULT=RESULT-Pi-1,j;
(3)在EXCLK的第2個(gè)時(shí)鐘鎖存RUSELT,由SRAM讀入Pi,j-1,并做減法運(yùn)算RESULT=RESULT-Pi,j-1;
(4)在EXCLK的第3個(gè)時(shí)鐘鎖存RUSELT,同時(shí)寫(xiě)入Pi,j











評(píng)論